Novels usually do not fail because nothing happens. They fail because the pattern collapses. Tone drifts, world rules soften, moral gravity wobbles, and whatever felt sharp in the first fifty pages dissolves into “something like this” by the last hundred. A language model accelerates both sides of that problem. It can produce enormous volumes of plausible prose, and it can quietly pull the work away from the very law that makes it worth writing.
The common advice about prompting—be clear, be specific, give examples—is good enough for grocery lists and cover letters. GPT-based long-form fiction, a rapidly growing and metastasizing product line, demands something closer to a containment protocol. In an environment already saturated with mediocre advice (much of it itself machine-generated), “Advanced Prompting” only earns the moniker when it counteracts drift at structural depth. Accordingly, every prompt in this series is an instrument for steering cognition within constraints that the model cannot see but will obey.
Skilled operators do not rely on single-turn cleverness or magic phrases. They design prompts that self-regulate, learn from failure, and reveal the model’s internal reasoning before a single sentence gets written. This is true in other writing disciplines, too, where quality matters at least as much, if not more. Me, I have developed a Refusal-Based Prompting methodology that applies seamlessly to short fiction, but is not specialized enough on its own to handle its longer forms. Therefore, this series bridges the gap by design, not discovery. What makes the prompt philosophy displayed here especially valuable is its transferability to entirely different adversarial domains, such as project management, sales/marketing copy, or litigation.
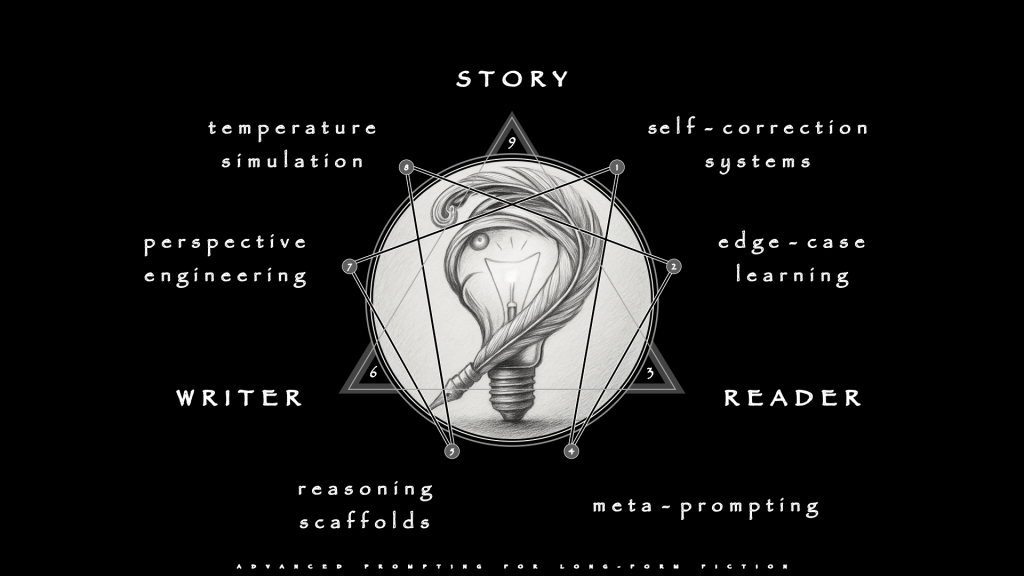
The architecture’s blueprint, or flowchart, is shown here on the enneagram as the Six Pillars of Advanced Prompting.
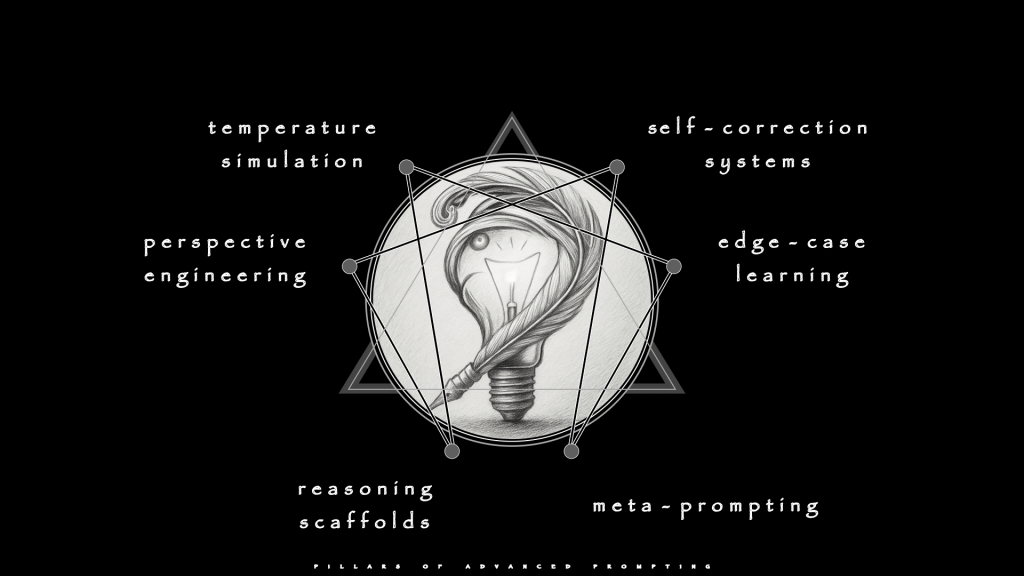
Each represents a mode of control, a way to shape the model’s thought rather than only its surface language. Technical writing uses these same domains for precision and defensibility. Long-form fiction uses them to defend Story-law, deepen character, keep dialogue honest, and carry emotional pressure across hundreds of pages. The difference is stakes. If a technical manual that drifts becomes annoying, a novel that does so is a betrayal.
As always Three Forces set those stakes, and they are not negotiable. The model never initiates. The machine can only complete patterns that the Writer thinks to present. Most failures occur when (or because) the Writer mistakes the model’s fluency for partnership and abdicates that authority, or authorship itself.
The Story (3) acts as the law: the coherent world, moral physics, and tonal range that decide what belongs. The Reader (2) receives the shocks, the boredom, the trust, and the resentment that accumulate over time. The Writer (1) initiates every move, including every prompt.
Three scales of stress sit under those forces. Scenes handle immediate experience. Chapters handle shifts in understanding and leverage. Whole novels handle obligation: promises made, questions raised, patterns opened, debts paid or left deliberately unpaid. Dialogue cuts across all three. Lines spoken aloud reveal whether the Story’s law, the Reader’s tolerance, and the Writer’s discipline are actually aligned. Thus dialogue becomes the final test of every prompt design. Fake history, fake philosophy, and fake remorse all advertise themselves the moment a character opens their mouth.
To examine how these pressures operate in practice, forensically, consider the following novels that solved long-form problems without any algorithmic assistance as canonical:
- Burr (1973), Gore Vidal – Aaron Burr dictates his version of early American history to a young journalist because he needs to seize control of how posterity remembers him. He seeks a self-justifying narrative in which his betrayals and schemes become hard realism rather than treason, and he fights against public vilification, political defeat, and his own talent for self-deception. The book operates as a historiographic political novel, which makes it ideal for investigating prompts that handle layered documents, unreliable narrators, and competing versions of the same event without losing structural coherence.
- Shibumi (1979), Trevanian – Nicolai Hel pursues a life of quiet excellence and “shibumi” while the modern intelligence world refuses to leave him alone. He needs a private code and a very small circle of loyalties that feel cleaner than the systems that trained and exploited him, and he pushes back against corporate espionage, bureaucratic stupidity, and his own attraction to elegant violence in order to keep some form of inner equilibrium. The Story functions as a high-competence espionage thriller, which makes it a sharp test bed for prompts that must preserve restraint, recurring scene patterns, and philosophical minimalism under genre pressure.
- Winter’s Tale (1983), Mark Helprin – Peter Lake and the people who intersect his orbit search for a place, a love, and a justice that make sense inside a New York stretched across time. They need to believe that beauty, loyalty, and miracles can stand against brutality, poverty, and loss, and they confront death, exile, and the cold machinery of the city itself while they try to carve out a pocket of meaning that does not evaporate. The work operates as mythic urban fantasy, which makes it perfectly suited for examining prompts that manage lush language, large-scale magic, and tonal brinkmanship without sliding into kitsch or self-indulgence.
- Perfume (1985), Patrick Süskind – Jean-Baptiste Grenouille grows up as an unwanted creature who believes he can only exist by distilling the perfect scent. He needs a constructed aura that compensates for his own lack of smell and his inability to connect with other human beings, and he moves through poverty, disgust, and murder while battling nothing in himself except the emptiness that finally swallows him. The narrative stands as a grotesque psychological novel, which makes it an exacting probe for prompts that enforce a single-sense perception law and maintain a very narrow, dangerous tone over an entire book.
- Watchmen (1987), Alan Moore and Dave Gibbons – A scattered community of costumed adventurers and ex-heroes struggles to understand what heroism means in a world that has moved on from simple villains. They need a Story about themselves that justifies masks, violence, and power in the face of nuclear terror and moral fatigue, and they face conspiracies, state power, and their own compromises while they decide whether saving the world is worth the cost of lying to it forever. The work functions as a formally aggressive graphic narrative, which makes it ideal for testing prompts that coordinate nonlinear structure, multiple document types, and clashing moral viewpoints without losing control of pacing or theme.
- Shantaram (2003), Gregory David Roberts – An escaped Australian convict called Lin washes up in Bombay and starts rebuilding a life among gangsters, slum dwellers, and exiles. He needs forgiveness, belonging, and a version of himself that feels larger than the crimes and addictions he carries, and he passes through prisons, wars, and love affairs while wrestling with his own hunger for drama and redemption that constantly threatens to undo his progress. The book behaves as a sprawling quasi-memoir, which makes it the hardest possible case for prompts that must manage length, digression, vanity, and plausibility without letting the whole structure drift into self-caricature.
The entire argument of this long-form essay is confined to these six. Furthermore, their order is nonrandom. Individually, each occupies a distinct position in the working geometry. In concert, the set is an optimized theoretical bottleneck of any prompting strategy. Can it reach the standard these novels established? Or, is it merely a pastiche engine, producing superficial knock-offs that collapse under the same pressures the originals survive?

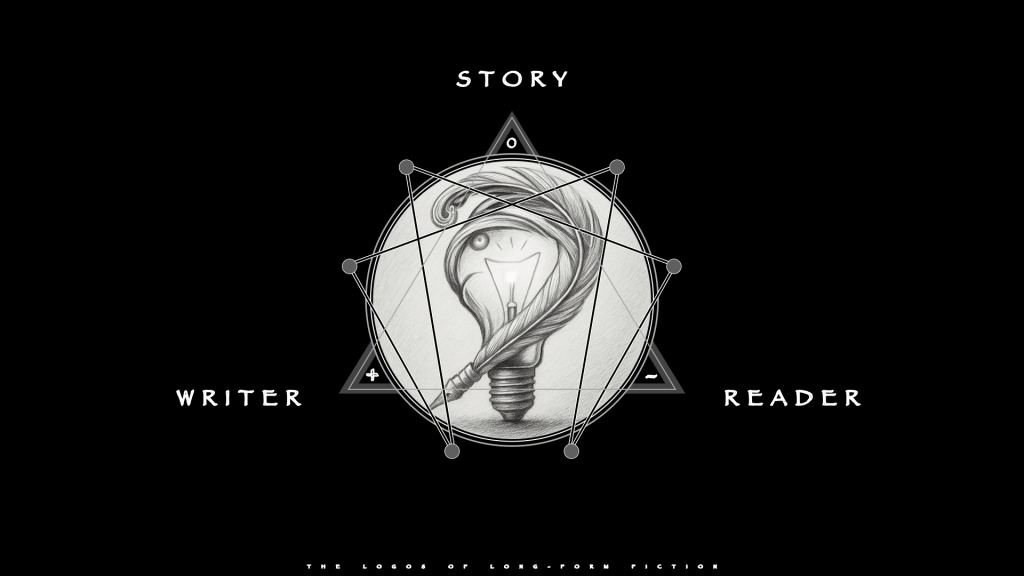
The Logos
Long-form fiction, whether novels or screenplays, is a 321 triad, Creation.
The Story (0) sits at the zenith as reconciling force, the medium that permits the Writer (+) and the Reader (-) to meet without canceling each other. The former initiates, the latter resists, and the Story (0) governs what result survives. This is not collaboration. This is a formal example of the Law of Three.
The Story (0) outranks everyone involved. Burr can tolerate a charming anecdote about Jeffersonian hypocrisy, yet it cannot tolerate patriotic hagiography without becoming another book. Perfume permits grotesque sensuality and murder, yet it refuses sentimental redemption for Grenouille. Winter’s Tale handles a flying horse and a time-bending cloud wall, yet it will not accept superhero banter inside its miracles. Each of these works discovered a law and obeyed it the way a suspension bridge obeys tensile limits—not out of virtue, but because violation means collapse.

The Reader (-) does not legislate that law, but tests it. Readers halfway through Shantaram have accepted a certain level of digression, sermon, and slum detail, and that same Reader will feel cheated by a clean, short wrap-up that ignores half the debts that the Story (0) incurred. A Reader (-) inside Watchmen has learned to expect recursion, visual echoes, and moral ambiguity; that Reader (-) will reject any late speech that tries to tell them what to think. Every chapter and every line of dialogue runs into that moving test. The Reader (-) is the load. The Story (0) either bears it or buckles.
The Writer (+) initiates every intervention. He chooses which scenes to draft, which voices to trust, which prompts to build, and which outputs deserve deletion. Trevanian decides whether Hel in Shibumi speaks in spare, acid lines or in padded genre banter. Gregory David Roberts decides whether Lin in Shantaram sounds like a man in trouble or a man rehearsing an after-dinner story. Like genre, a model never initiates anything. It only reveals what the current system design will permit.
Scenes show whether the law holds under pressure. Chapters show whether the Reader’s beliefs and expectations are being managed with any respect. The full book reveals whether the Writer (+) actually paid what the Story (0)demanded. Dialogue runs through all three scales, because spoken lines expose every fake: fake history, fake philosophy, fake remorse, fake myth. A character can lie. The dialogue cannot.
Long-form fiction operates as a three-force system. When the three meet correctly, the result is art. When they don’t, the Writer (+) produces pages that the Reader (-) will not carry; or, the Reader (-) demands comfort that the Story (0)cannot give; or, the Story (0) drifts until no one remembers what it was supposed to be.
The geometry is strict. The pillars are only interesting when they keep that geometry intact. Otherwise they become sophisticated ways to generate forgettable (or unread) pages.
Self-Correction treats the LLM both as a worker (i.e. craftsman) and a critic (i.e. client) in the same breath. This is no Auto-Humiliation ritual, either. The operative aim at this juncture is to drag hidden defaults into daylight before they harden into the foundation.
Burr shows what is at stake when voice is law.
Aaron Burr dictates his version of early American history to a young journalist. Every claim must therefore sound like partisan spin, not omniscient truth. Burr, as a character, is self-serving, charming, occasionally dishonest, and always aware that he is performing for an audience whom he hopes to seduce. A naive prompt that requests “Burr describes the duel with Hamilton” will produce clean, neutral history. Models have been trained on encyclopedia entries and textbook summaries; they know the facts, and will deliver them with the tonal flattening that makes historical fiction feel like a lecture.
A Self-Correction loop can refuse that drift. A first pass, for example, demands a draft wherein Burr’s account serves his own interests—minimizing his malice, exaggerating Hamilton’s provocations, sliding blame toward Federalist myth-makers. The second pass thus orders the LLM to become a hostile historian who flags every line where Burr sounds objective, every moment where the narration grants him omniscient knowledge he could not possess, and every paragraph where the voice loses its edge of self-justification. The model would mark lines like “Hamilton’s political maneuvering had grown desperate” as too neutral. Burr would never grant Hamilton that dignity without wrapping it in a barb. Finally, a third pass rewrites only flagged lines, forcing the voice back into motivated unreliability.
The loop does not, indeed cannot, create Gore Vidal, or even simulate him, per se. No, loops prevent an LLM from quietly replacing Burr’s corrosive memoir with a History Channel special. Without it, the voice smooths into something respectable, and the entire architecture collapses.
Dialogue demands even stricter discipline.
When Burr speaks to Schuyler, he is performing a seduction—intellectual, not sexual, but a seduction nonetheless. A quick “write the conversation where Burr explains his view of Jefferson” prompt will produce balanced debate. Burr will make cogent points, Schuyler will offer thoughtful counterarguments, and both will sound like they are modeling civil discourse for a classroom. That is narrative suffocation. Self-Correction Systems force a refinement pass to mark every line where Burr is teaching rather than manipulating, and another for every moment where Schuyler’s resistance becomes too articulate. Target moments where the power dynamic flattens, and raise the stakes. What remains should feel like a dance, not a debate.

Winter’s Tale exposes self-correction on a different front. The work declares its octave early: mythic urban fantasy soaked in beauty, miracles, and impossible love. The novel shamelessly handles a flying white horse and a cloud wall that bends time, fused with an unapologetically romantic metaphysics. The risk is constant. One degree too far and it becomes self-parody. One degree too cautious and it betrays its own premise.
LLMs will drift in both directions. Left unchecked, they will either amplify the lyricism until the prose drowns in its own honey, or rationalize the magic in ways that drain the mystery. A prompt that requests “Peter Lake’s first flight on the horse” will produce one of two failures: purple excess where every sentence aches with beauty and nothing happens, or explainer mode where the narrative starts offering physics for the impossible.
Here, in this complicated case, a Self-Correction loop must defend the declared tone against both drifts. It is a challenging genre. For the first pass, the writer would demand a draft that honors the miraculous without flinching—no hedging, no winking at the Reader. The second pass orders the model to become a skeptical Reader of Winter’s Tale itself, someone who loves the book and will reject any line that betrays its law. This Reader flags sentences where beauty becomes ornamental rather than structural, and moments where the miracle gets domesticated into genre convention.
The model might mark “The horse’s wings shimmered with an otherworldly iridescence, as if woven from starlight and dreams” as sentimental kitsch—beauty for its own sake. It might also mark “Peter gripped the reins and pulled back, sending the horse into a steep climb” as superhero banter. The third pass rewrites only flagged lines, holding the tone steady between awe and inevitability. As before, the loop does not recreate Mark Helprin. It prevents the model from quietly replacing Winter’s Tale’s disciplined extravagance with either mawkish sentiment or genre mechanics.
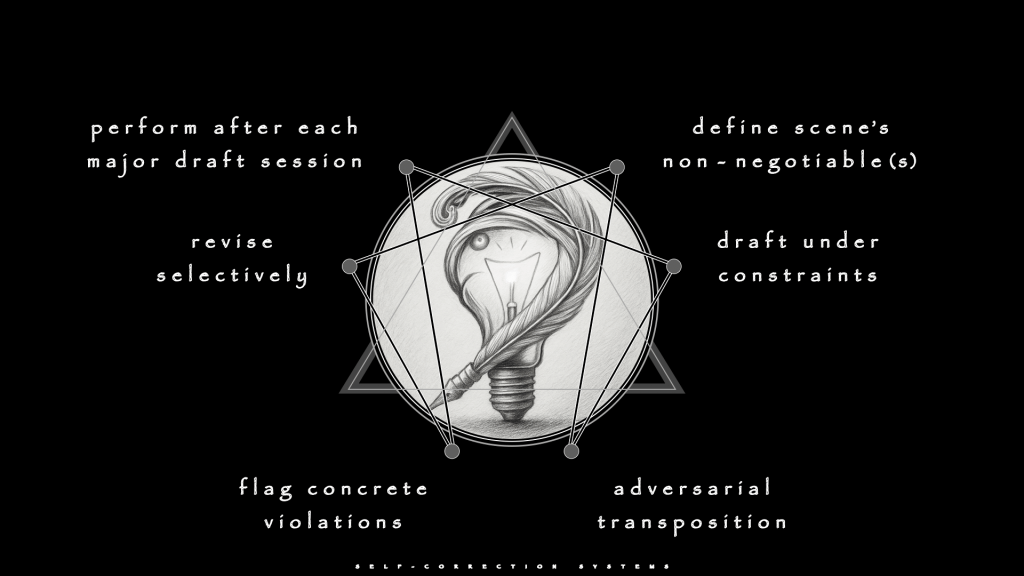
Effective Self-Correction loops operate in stages. Begin by defining a scene’s non-negotiables. Draft under those constraints, knowing the first pass will drift. Switch roles into a hostile critic who knows that law and has no patience for violations. Flag the failures with line-level evidence to filter out the drift. Then, rather than rewriting everything from scratch, revise selectively. Finally, do not wait for the rot to spread, but instead repeat the process after each substantial drafting session.
Without that critical engine, advanced prompting gravitates toward comfort. Every unreliable narrator becomes a charming rogue who is mostly honest. Every miracle becomes a special effect. None of those defaults belong in Burr or Winter’s Tale unless the Story-law explicitly invites them.
Edge-Case Learning: Living Near the Cliff
Edge-Case Learning trains taste instead of imitation. Clean examples show what belongs. Near-misses show where the cliff begins. Long-form fiction spends its life walking that edge, and the cliff is not failure. The cliff is self-parody—the moment competence becomes cartoon, beauty becomes kitsch, or grandiosity becomes a joke.
Rather than attempting to force a specific output based on your imagination, the technique exploits a simple asymmetry in how LLMs work: They are better at recognition than creation.
They can spot violations more reliably than they can invent solutions. Edge-Case training uses that strength deliberately: generate near-misses, then force the model to explain why they fail. The explanation sharpens the Writer’s own judgment before drift sets in. The sum of the lessons-learned (minus whatever the Writer decides to exclude) may be incorporated into the next prompt, which can even be written by the chosen model itself.
A simple sequence might run thus:
- “How can this be improved?” (Begin with any rules you saw violated, if necessary)
- “What is your correction plan?” (Preceded by any requirements you have, if relevant)
- “Proceed” (Assuming no major flags, otherwise reiterate prior step)
Shibumi lives on such a ridge, almost mocking the genre without ever mocking the Reader. Nicolai Hel is presented as a man of near-superhuman competence: polyglot, master spelunker, skilled in proximity sense, lethal in an esoteric martial discipline, aesthetically refined to the point of arrogance. The novel deftly survives this catalog of abilities because Trevanian knows exactly how much competence the Reader will tolerate before admiration curdles into eye-rolling. One more implausible skill, one more scene where Hel effortlessly dominates an opponent, and the character becomes a cartoon.
This would be Perspective Engineering failure, where character competence crosses into parody, and the Reader deflects rather than absorbs.
A Writer who uses a model for that kind of material can ask for several variants of a key scene and then force the model to critique them. Take, for example, a hypothetical clash where Hel faces a trained operative in close quarters. One variant might have him dispatch the threat in two moves with clinical efficiency. Another might give Hel a moment of genuine physical vulnerability before his skill reasserts itself. A third might add internal monologue where he reflects on the philosophy of violence mid-fight.
The critic-role must articulate why the original balance works and why the variants fail. The first variant (effortless dominance) makes Hel boring—competence without cost. The third variant (philosophical digression) breaks the tonal law that Hel never explains what he can simply do. The second variant might be the only one that holds: brief vulnerability that reminds the Reader that Hel is mortal, followed by disciplined resolution that reaffirms his mastery.
Dialogue in Shibumi walks an even finer edge.
Hel’s speech is laconic, precise, occasionally cruel. He speaks in understatement and implication, never stating what he can suggest. A single exchange where Hel over-explains or softens into sentiment would shatter the character. When dialogue switches genre in a single exchange, then the slope that made Hel credible inverts into therapy-speak or action-movie banter.
Edge-Case prompts can test that boundary by generating three versions of a conversation between Hel and a bureaucrat: one where Hel is more verbose than usual, one where he is more overtly contemptuous, and one where he allows a moment of warmth. The ranking exercise clarifies which versions violate the tonal law and which merely stretch it. Verbosity breaks the character. Overt contempt might work, if brief and triggered by genuine provocation. Warmth is the hardest judgment: a single sentence of unexpected humanity could deepen Hel, or it could collapse him into a stock figure. The Writer must decide, but the Edge-Case variants make the decision explicit rather than intuitive.

Without this training, the Writer and the model become gradually desensitized to drift.
Each session’s output may feel “good enough” because the model produces fluent, plausible prose. The problem is not that any single scene fails catastrophically. Success with the technique will depend on the Story; the same failure will look different in another novel. In Shibumi , the problem is that accumulated micro-violations—Hel slightly more talkative here, slightly warmer there—compound across chapters until the character becomes unrecognizable.
Edge-Case work interrupts that drift by making violations visible before they harden.
Shantaram exposes Edge-Case Learning on a different front. Lin’s narrating voice is grandiose, digressive, and in love with its own sound. The novel survives because Roberts calibrates exactly how much performance the Reader will tolerate before affection turns to irritation. One more sermon, one more philosophical tangent that resolves too neatly, and the Reader begins to suspect Lin is less interested in truth than in how he sounds telling it. When authorial opinion overwhelms Story logic, what should feel like hard-won insight collapses into vanity.
A Writer who uses a model for Shantaram-style material can ask for tonal variants of a key reflection. Take a scene where Lin reflects on what the slum has taught him. One variant leans into earnest uplift. Another adds self-awareness. A third strips the reflection entirely and lets the scene speak through action.
The critic-role must explain why the original balance holds and why the variants collapse. Earnest uplift turns Lin into a motivational speaker. Stripped action abandons the voice that makes the book distinct. Self-awareness—Lin performing while acknowledging the performance—might be the only variant that works. That judgment is not obvious. The Edge-Case variants force the Writer to articulate why.
Edge-Case prompts strengthen discrimination across the geometry; critic-roles simply make them inspectable before drift makes them irreversible.
Meta-Prompting: Building the Control Panel
Meta-Prompting turns the chosen model into its own engineer. Rather than issuing ad-hoc commands forever, the Writer demands that the LLM design the best possible prompt for a particular recurring task, then tests and refines the design. The result becomes part of the novel’s control panel—a set of reusable templates that prevent the same mistakes from recurring across sessions.
Think of it as a pilot’s pre-flight checklist. The checklist does not fly the plane, but it ensures that critical procedures are never skipped due to fatigue, distraction, or overconfidence. Without Meta-Prompting, the Writer re-explains the same constraints in every session. The explanations will drift slightly each time, and the model’s understanding of the Story’s law becomes inconsistent. A common problem is that a scene drafted in Week 1 of the process obeys rules that a scene drafted in Week 10 quietly abandons. By Week 20, the novel will fracture into incompatible tonal registers.
Winter’s Tale invites Meta-Prompting because it cycles through distinct structural moves: mythic encounters with the white horse, cloud wall appearances, urban New York scenes grounded in physical detail, and moments where metaphysics and romance fuse without explanation. These are recurring scene-types specific to the book. A Meta-Prompt for “mythic encounter” can ask the model, in a deliberately reflective role, to list the ingredients of such a scene: the miraculous element treated as inevitable, precise physical grounding before and after the miracle, emotional stakes tied to a character’s deepest need, and no rationalization or winking at the Reader.

The Writer then uses that list to build a standard prompt for drafting any new mythic moment. Later refinements add constraints: how much beauty is permitted before lushness becomes ornament, how many metaphysical assertions can appear in a single scene before the Reader’s tolerance breaks, and what ratio of grounded detail to miracle maintains believability. The Meta-Prompt does not write the scene. Rather, it defines the boundaries that keep a novel such as Winter’s Tale from drifting into generic fantasy or self-parody.
The novel also contains recurring image patterns: the cloud wall, the horse, specific New York architecture functioning as omen or anchor. A Meta-Prompt can instruct the model to analyze how these images are deployed across the existing text and propose outline patterns for chapters that will reintroduce them. For instance, the template might specify: “The image must appear with fresh context, it cannot be weaker than its last appearance, and it must serve structure (judgment, rescue, echo) rather than decoration.” That move protects the Story’s symbolic integrity against the model’s habit of recycling motifs until they lose force.
Shibumi benefits even more from Meta-Prompting because it contains tightly defined recurring conversational setups. Hel sits across a board, a table, or a battlefield from bureaucrats, pupils, or adversaries. The conversations follow a pattern: Hel speaks in spare lines, the other party either overexplains or underestimates him, and the exchange ends with Hel establishing dominance through implication rather than declaration. A Meta-Prompt can define “Hel-style philosophical exchange” as a type: three short volleys maximum, one illustrative anecdote if absolutely necessary, one implied insult, and never a page of dialectic.
Once that definition exists, later prompts can refer to it instead of giving the model free rein.
The same approach applies to Shibumi’s action sequences. Hel’s combat is never extended brawling. It is brief, precise, and often ends before the opponent realizes the fight has begun. A Meta-Prompt can ask the model to analyze existing combat scenes and propose a template: “opening setup (terrain, threat assessment), single decisive action or feint, resolution in two moves or less, and no extended choreography”. The template then governs any new encounters. That discipline prevents the model from drifting into generic thriller pacing where fights extend to fill dramatic space rather than serving character logic.
Both novels would also benefit from Meta-Prompts that define what not to do, if they were written via GPT. For Winter’s Tale, a “forbidden moves” Meta-Prompt might specify: no explaining the horse’s origin, no dialogue where characters discuss whether magic is real, no plot that turns the cloud wall into a weapon or tool, and no sentimentality in romantic scenes. For Shibumi, the forbidden list might include: no internal monologue where Hel doubts himself, no scenes where bureaucrats are secretly competent, no extended descriptions of Gō tactics, and no dialogue where Hel offers comfort or reassurance.
The advantage of Meta-Prompting is that it externalizes taste into reusable architecture. A Writer working on Winter’s Tale-style material does not need to re-explain “treat miracles as inevitable, not explained” in every drafting session. The Meta-Prompt handles that constraint automatically. A Writer working on Shibumi-style material does not need to remind the model every time that Hel speaks in understatement. The template enforces it. The control panel prevents drift before it starts.
Reasoning Scaffolds: Keeping the Spine
Reasoning Scaffolds give the model a skeleton and refuse to let it skip straight to pretty sentences. The ideal is not verbosity, after all, but thought made visible. LLMs optimize for local coherence—sentence follows sentence smoothly—over global coherence, whereas a scene must serve the novel’s entire architecture. Scaffolds interrupt that local optimization by forcing global questions be answered first. The model may not begin polishing prose until it has answered: what does this scene accomplish structurally, and how does it avoid repeating earlier beats in weaker form?
Perfume exposes the need in raw terms. Consider the early scene where Grenouille and Baldini meet, and recruit each other. This is dramatically rich because it operates as reciprocal transformation disguised as negotiation. Both characters change permanently, but through completely different mechanisms. Grenouille gains access to methodology and legitimacy. Baldini gains competitive advantage and unknowingly dooms himself. The scene must balance their asymmetric awareness—Grenouille knows exactly what he is doing, while Baldini thinks he is being shrewd and is actually being exploited.
Without a Scaffold, a model will produce a charming encounter between master and prodigy. The prose will be fluent. The dialogue will crackle. Baldini will sound wise, Grenouille will seem grateful, and the entire exchange will betray the book’s law. A Perfume-aware Scaffold demands a map, the scent-architecture of the space.
Baldini’s shop smells of old formulas, dust, commercial failure, and desperation. Grenouille’s scent profile remains absent—his lack of smell is the hook. The perfumes Grenouille recreates (Pélissier’s “Amor and Psyche” as the test case) must be logged with their function: proof of competence, not artistry. Emotional scent-markers must be explicit: Baldini’s anxiety registers as sweat mixed with old tonics; Grenouille’s hunger registers as absence seeking presence.
Next, map the power dynamic through scent knowledge.
What Baldini smells: competence, threat, opportunity. He reads Grenouille as a tool. What Grenouille smells: decay, obsolescence, exploitability. He reads Baldini as a gateway. The asymmetry must be preserved: Baldini thinks he is in control because he owns the shop; Grenouille is in control because he owns the knowledge.
Then, define the structural function of the encounter.
For Grenouille, this is the transition from street savage to apprentice—access to distillation turns instinct into methodology. For Baldini, this is short-term salvation and long-term doom. His formulas revive the business, but he becomes dependent on a force that he cannot understand or control. For the Story, this is the threshold where Grenouille’s murders cease being accidents and become systematic harvest.

Something must shift by scene’s end. Grenouille’s status changes from invisible vagabond to indispensable asset. Baldini’s fate shifts from failing craftsman to temporarily successful exploiter whose fate is sealed. The Reader’s understanding must harden: Grenouille is not lucky or sympathetic. He is predatory and patient.
Consider the dialogue constraints. Baldini speaks like a man clinging to dignity: verbose, anxious, self-important. Grenouille remains minimal and transactional, never explaining when he can demonstrate. No warmth exists between them. No mentorship. The exchange is purely extractive on both sides.
Only after that Scaffold exists may the model draft prose. The Writer can then see the Scaffold on its own and immediately determine whether or not the scene respects the Story’s law and structural weight. If the scent-map is thin, if the power asymmetry flattens, if Baldini becomes a kindly mentor, the Scaffold catches those failures before they are buried in 500 words of polished dialogue.
The Scaffold is not the scene. The Scaffold is the load-bearing frame that prevents the scene from collapsing into a well-written moment that serves nothing. Without it, the model will optimize for charm and fluency, producing an encounter that feels right in isolation but quietly replaces Perfume’s predatory logic with generic apprenticeship narrative.
The same discipline applies to Watchmen, though at higher complexity. Before drafting Doctor Manhattan’s chapter on Mars, the Scaffold must map non-linear time (which past and future moments appear, and why), fractal structure (the clockwork palace as visual metaphor for determinism), moral function (this chapter decides whether the book has a compassionate center or only cold logic), and what Laurie’s presence must accomplish to shift Doctor Manhattan’s detachment. The Scaffold forces those structural relationships into explicit view before a single panel description exists. Otherwise the chapter becomes a beautiful meditation on godhood that fails to bear the weight the book’s ending requires.
A Scaffold operates at higher abstraction than dialogue or description. It answers: what must this scene accomplish structurally, what constraints must it obey, and what would failure look like? Only after those questions are answered explicitly does the model begin generating prose. That sequence—structure before sentences—is the only reliable way to prevent models from optimizing for local fluency at the expense of global coherence.

Perspective Engineering: Topology of Minds
Perspective Engineering multiplies minds on demand. Polyphony, artful as it may be, Perspective Engineering multiplies minds on demand. Polyphony, artful as it may be, cannot be narrative a purpose unto itself. Therefore, these prompts aim to prevent the Story from collapsing into a single moral lens disguised as omniscience. The technique exploits another asymmetry in how LLMs operate.
Models more easily recognize POV violations than they maintain POV consistency.
By forcing explicit switching between Perspectives, the Writer makes the model’s default omniscience visible and breakable. A model undirected will drift toward a narrator who sounds reasonable, balanced, and morally coherent. The bland voice that results, while adequate for a newsfeed, would belong neither in Watchmen nor in Burr.
Watchmen makes the need obvious. Rorschach, Dan, Laurie, Doctor Manhattan, and Veidt inhabit different moral geometries. Rorschach sees the world in absolutes: evil must be punished, compromise is corruption, the mask is the true face. Dan clings to nostalgia and fears irrelevance. Laurie resents being defined by others’ expectations. Doctor Manhattan experiences all time simultaneously and struggles to care about human-scale morality. Veidt believes the ends justify any means and operates in cold utilitarian calculus. These are not variations on a theme. These are incompatible moral operating systems.
For example, a test-prompt that asks the model to retell a key sequence—the Comedian’s funeral, the final showdown in Antarctica, or Rorschach’s fateful decision—in the interior voice of each character exposes what the current draft over-privileges. This is a fictional, or hypothetical example, however your own work must pass the same test. Therefore, your chosen model must be trained to articulate:
- What does Rorschach see in this moment that Doctor Manhattan cannot?
- What does Dan feel that Veidt dismisses as weakness?
- What does Laurie understand that the men miss entirely?
A separate critic-role can then report on which interiority the book currently treats as authoritative and whether that choice matches the intended emphasis.
When the model drafts the Antarctica showdown, for example, a prompt can force it to generate the scene from Veidt’s interior first: calm, certain, already mourning the necessity of what he has done. Then from Rorschach’s interior: rage, betrayal, the unbearable clarity that the world will call this victory. Then from Dan’s interior: moral paralysis, the sickening realization that silence might be the only sane choice. Then from Doctor Manhattan’s interior: detachment breaking under Laurie’s earlier argument, the faint stirring of care arriving too late to matter.
Done well, each version reveals what the others suppress . . .

After drafting, the Writer applies a diagnostic test: whose version of events does this scene privilege? If the answer is “objective truth” rather than a named character’s Perspective, the scene has already failed. Watchmen refuses omniscience. The correct balance is unbearable tension where the Reader must choose without guidance. Perspective Engineering makes that tension auditable.
Burr lives on multiple planes of Perspective, though in a different architecture. Burr speaks in retrospect, dictating his version of history to the young journalist Schuyler. Every claim Burr makes serves Burr’s interests: minimizing his malice, exaggerating his enemies’ provocations, reframing betrayals as necessity. Schuyler listens, filters, and occasionally resists, though he is half-seduced before the conversation begins. Federalist newspapers, letters, and future historians stand around the edges, each with their own partisan goals.
Perspective prompts can assign distinct objectives to each viewpoint: Burr seeks self-exoneration, Schuyler seeks career advancement through proximity to scandal, Federalist editors seek partisan attack, and future historians seek myth-making that serves national cohesion. The model can then generate marginalia, as if each Perspective were scribbling in the margins of the same scene. Those imaginary comments reveal whose Story is actually being told. If every scene reads as Burr Triumphant, the book has collapsed into hagiography. If every scene reads as Burr Exposed, the book has collapsed into prosecution. The correct balance is Burr performing self-justification so skillfully that the Reader must do the work of separating charm from truth.
Dialogue is where Perspective collapses most visibly.
When all characters start sounding equally articulate, equally self-aware, and equally capable of explaining their own motivations, Perspective has died. Rorschach should not sound like Doctor Manhattan. Burr should not sound like a neutral historian. A Perspective-Engineering pass can treat individual exchanges as transcripts submitted to different reviewers. When Burr and Schuyler argue over Jefferson’s legacy, the model can be prompted to generate responses from three Perspectives: Burr’s private assessment (did he move Schuyler closer to belief?), Schuyler’s private assessment (did Burr overreach and reveal his bitterness?), and a Federalist Reader’s reaction (does this passage confirm Burr’s unfitness?). That feedback does not rewrite the dialogue automatically. It stops the Writer from mistaking Burr’s performance for honesty or mistaking Schuyler’s resistance for independence.
Useful Perspective work typically operates through several distinct lenses:
- protagonist interior
- close ally or lover
- institutional or bureaucratic voice
- outsider of lower status
- outsider of higher status or power
- critical future Reader or historian
Prompts can route scenes and dialogues through different combinations of these lenses whenever the topology of minds begins to flatten.
The diagnostic remains simple: after every major scene or dialogue, ask the model whose Perspective dominates. If the answer is “no one in particular” or “the Story itself,” Perspective has collapsed into false omniscience. The goal is not neutral objectivity. The goal is preserving the moral complexity that makes the Story worth reading.
Temperature Simulation: Modes, not Sliders
Temperature describes how wild or cautious the model’s choices feel. Interfaces Temperature describes how wild or cautious the model’s choices feel. Interfaces hide it behind a slider. System design can simulate it with roles.
Roles work better than raw Temperature adjustment because they carry context and constraints that numerical settings cannot. A _cold magistrate_ knows what it is defending—the Story’s law, the Reader’s tolerance, the structural debts still unpaid. “Temperature 0.2” knows nothing. It simply narrows the model’s sampling distribution without understanding why caution matters here or what rules should govern the pruning.
Roles make Temperature accountable.
High-Temperature modes explore; Low-Temperature modes judge. A Writer should have no preference; both are necessary. Perfume’s final tone would not hold without savage pruning. Shantaram, in particular, shows what can happen when High-Temperature narration runs unchecked. The novel becomes enormous and intoxicating, and any further escalation would turn it into a joke.
Roles can make these modes explicit:
- generative architect proposes extreme moves
- cold magistrate defends Story-law against those proposals
- internal witness handles pure interior monologue and emotional truth
- external critic speaks as a demanding Reader of the specific lineage
- structural engineer manages acts and debts rather than sentences
- line surgeon orchestrates rhythm and compression
Shantaram lives at the edge of Temperature failure. Lin’s narrating voice is grandiose, digressive, performative, and in love with its own sound. The book survives because Roberts calibrates exactly how much exuberance the Reader will tolerate before affection curdles into irritation. LLMs will cheerfully amplify Lin’s tendencies until their output becomes unbearable. The risk is that every reflection becomes a sermon, every conversation becomes a set piece, and every hardship becomes an opportunity for philosophical proclamation.
A Temperature-aware system can simulate Lin’s voice through alternating roles. The generative architect mode drafts a slum scene with maximum indulgence: sensory detail, philosophical tangents, emotional swells, and Lin’s relentless need to make meaning out of chaos. The output might run three thousand words and include lines that sound profound in isolation but accumulate into parody. That draft is not the goal. That draft is the pressure test—the same technique Edge-Case Learning uses to find the cliff where daring becomes ridiculous.
The cold magistrate role then attacks. This voice knows Shantaram’s law: Lin can perform, but the performance must crack under its own weight often enough to preserve credibility. The magistrate flags every line where grandiosity becomes absurd, where sentiment replaces observation, and where Lin’s philosophy resolves too cleanly. The line surgeon follows, cutting the three thousand words to eight hundred without losing the voice’s essential texture. What remains should still sound like Lin—digressive, self-aware, occasionally profound—but pruned to the point where the Reader’s trust holds.

Perfume requires Temperature discipline in the opposite direction. Grenouille’s world is compressed, narrow, and almost entirely olfactory. The book’s tone is grotesque, sensual, and ruthlessly unsentimental. A model’s default mode will either soften that tone (making Grenouille sympathetic) or explode it (making the grotesquery cartoonish). Both failures kill the novel.
A Temperature-aware system for Perfume deploys the generative architect sparingly. For example, the model would be instructed to draft the “climax” scene with maximum sensory intensity but no moral commentary. The internal witnessrole produces Grenouille’s interior: pure hunger, emptiness discovering itself, the realization that even the perfect scent cannot fill what was never there. The output might be visceral to the point of nausea. That is the test. The cold magistrate then defends the book’s law: Grenouille gets no redemption, no sentimentality, no therapeutic backstory. The external critic speaks as a devoted Perfume Reader and rejects any version that flinches. The line surgeon tightens without softening.
Temperature Simulation (Point 8) connects directly to other domains. It feeds Edge-Case Learning (Point 2) by generating the extreme variants that reveal where the cliff begins. It depends on Reasoning Scaffolds (Point 5) to define what each role must accomplish structurally before it can shape sentences. A generative architect session without a Scaffold produces beautiful chaos. A cold magistrate session without Edge-Case awareness cannot distinguish between necessary severity and premature austerity.
The diagnostic test is simple: if every scene feels polished but the book feels aimless, you have been running cold magistrate too early. The structural engineer never mapped the spine, so the line surgeon is tightening scenes that serve nothing. If every scene explodes with invention but nothing connects, you have never really engaged the structural engineer or cold magistrate. The generative architect has been running unchecked, producing material that impresses in isolation and dissolves under the weight of a hundred pages.
Temperature Simulation prevents two symmetric failures: permanent brainstorming with no spine, and premature austerity that kills invention. Shantaram without generative exuberance becomes a travelogue. Shantaram without cold pruning becomes a joke. Perfume without generative intensity loses its visceral horror. Perfume without ruthless compression loses its alien precision.

Dialogue as Oath
An oath is public, binding, and survives only if kept. Every line of dialogue is an oath to the book’s law. Burr’s talk either serves Vidal’s malice toward national myth or slides into modern explanation. Hel’s words either serve Trevanian’s stripped code or drift toward generic spy chatter. Lin’s voice either serves Roberts’ dangerous blend of confession and performance or degenerates into travel-brochure spirituality.
Dialogue betrays drift faster than description because it is voice made audible. A description can hide behind beautiful prose, layered imagery, or structural misdirection. A spoken line cannot. The character either sounds like themselves or they do not. There is no middle ground. When a model supplies a perfect, self-aware quip, that line almost never belongs in Perfume, Winter’s Tale, or Burr. When a model produces a heartfelt confession that explains everything, that speech almost never belongs in Shibumi.
This is why dialogue is the integration test for all prior domains:
- Self-Correction loops flag on-the-nose statements and generic exposition
- Edge-Case experiments push speeches toward parody to find where restraint becomes cartoon and where eloquence becomes performance
- Meta-Prompts define scene-type signatures for talk—interrogation, confession, flirtation, debate—so the model knows what conversational grammar the book permits
- Scaffolds tie each line to scene purpose and structural function, preventing characters from talking because the model enjoys their voice rather than because the structure demands it
- Perspective passes show how different listeners mishear or resist what is said, keeping dialogue from collapsing into neutral exposition
- Temperature alternation moves between exuberant drafting and ruthless trimming, ensuring that eloquence earns its keep rather than becoming decoration
Shibumi and Shantaram make an instructive pair because they sit on opposite poles.
One operates in third person with a protagonist who hoards words. The other operates in first person with a narrator who spills them everywhere. Any serious use of models on those lineages must pass through dialogue bottleneck like a Borsalino hat through a wedding ring. If Hel sounds sentimental like Lin, the system has failed. Or, if Lin sounds like a washed-out thriller antihero, the system has failed more quietly but just as completely.
Again, the diagnostic test is simple: read the exchange aloud without dialogue tags. If you cannot tell which character is speaking, the voices have collapsed. Hel’s speech should be recognizable by its brevity and acid precision. Lin’s speech should be recognizable by its grandiosity and self-awareness. Burr’s speech should be recognizable by its charm wrapped around malice. If every character sounds equally articulate, equally self-aware, and equally capable of explaining their motivations in complete sentences, dialogue has died and been replaced by the model’s default narrator wearing different names.
Dialogue does not forgive. A single exchange where Grenouille explains his emptiness in therapeutic language collapses Perfume. A single scene where Hel becomes verbose destroys Shibumi. A single speech where Lin’s performance loses self-awareness turns Shantaram into parody. The model will produce those lines cheerfully. The system must refuse them ruthlessly. That refusal is the oath made visible.
Treating dialogue as oath keeps the whole enterprise honest.
A Writer who promises to cut any line that violates Story-law, no matter how clever the model made it, has already accepted the core obligation. The oath is not to the model’s fluency. The oath is not to the Writer’s vanity. The oath is to the work itself: the coherent world, the Reader’s trust, and the discipline that keeps both intact across hundreds of pages.
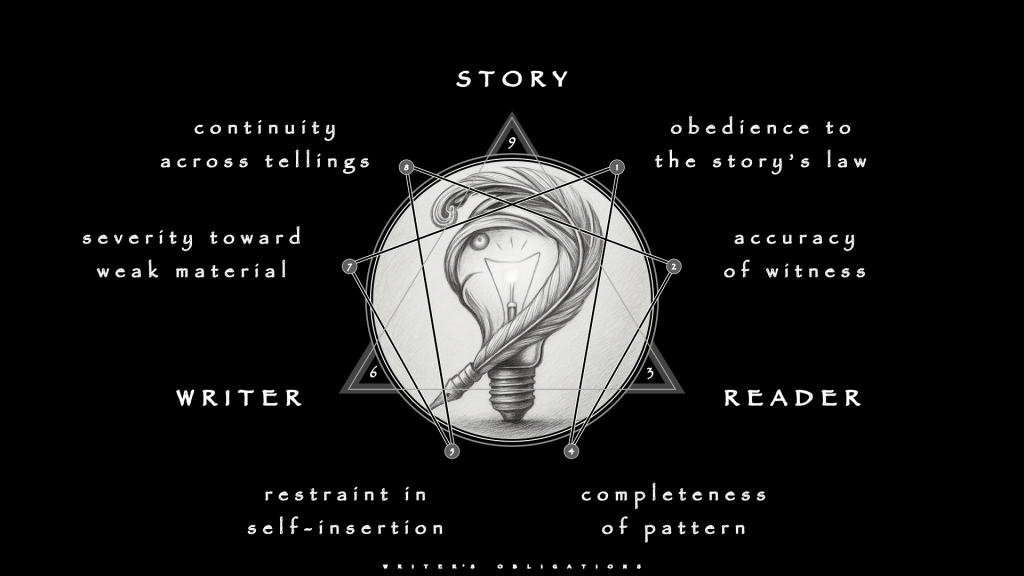
Obligations to the Story
Tools invite convenience. Long-form work survives only on duties. Older practice treated the Story (0) as senior partner and the Writer (+) as a temporary custodian. That stance does not change just because a language model can improvise any scene on demand.
These obligations enforce the hierarchy stated at the beginning: Story (0) governs, Writer (+) initiates, Reader (-) tests. The three forces remain constant. What changes is the speed at which a Writer (+) can betray them. A careless operator can now produce, in weeks, a convincing, hollow imitation of the works that solved long-form problems without algorithmic assistance. A disciplined operator can instead build a system that forces both Writer (+) and model to answer to something older and stricter than either of them.
Several obligations follow from that orientation.
Obedience to the Story’s (0) law forbids using a model to smuggle in easy devices from other lineages. Perfume does not suddenly owe the Reader (-) a therapeutic backstory for Grenouille. Watchmen does not suddenly owe the Reader (-) a speech that resolves its moral conflict. Accuracy of witness forbids using the model’s smoothing instinct to look away from what exploitation, violence, or corruption actually do in a Basque village or a Bombay slum.
Completeness of pattern forbids opening debts—prophecies, promises, ideological questions—and then abandoning them because the model supplied a more exciting subplot. Restraint in self-insertion forbids treating prompts as a megaphone for the Writer’s (+) unprocessed opinions, particularly in historical or political material. Severity toward weak material forbids hoarding output because “it took time to generate.” Continuity across tellings forbids letting each new model version or prompt fashion reinvent the book’s aesthetic for amusement.
A system that respects those obligations builds them into its own checks.
- Self-Correction prompts flag places where the narrative excuses or condemns characters beyond what the evidence supports.
- Edge-Case experiments specify dignity limits and refuse to cross them even when the model can produce something shocking._
- Meta-Prompt for revision remind the model that cuts should target authorial indulgence before they target difficulty.
- Scaffolds track debts, not just beats, and require a decision about every major one.
- Perspective work keeps the Writer (+) aware of who is being flattened or sentimentalized.
- Temperature roles give the severe, law-defending voices a regular seat at the table.
Every new prompting technique should face the same questions. Does the method respect the existing law of this Story’s (0) world? In Winter’s Tale, this means: does the new meta-prompt preserve the rule that miracles are never explained? In Burr, this means: does the self-correction pass catch every line where Burr sounds objective instead of self-serving? Does the method clarify what really happens and why, or obscure it? Does it help close patterns at the right scale, or proliferate loose ends? Does it serve the work rather than the Writer’s (+) urge to posture? Does it make cutting easier, or harder? Does it preserve the same book across drafts, or slowly replace it with a different one?
Applied to Burr, those questions highlight any temptation to insert twenty-first-century virtue into eighteenth-century mouths. Applied to Perfume, they highlight any attempt to redeem Grenouille because a model has learned to expect arcs. Applied to Watchmen, they highlight any urge to resolve ambiguity in a single late speech. Applied to Shibumi and Shantaram, they highlight the constant pressure to turn difficult, compromised figures into smooth avatars of ideology.
Advanced prompting does not change those obligations. It only raises the stakes. The speed becomes the problem, not the solution, unless the system enforces fidelity at every step. That system does not guarantee greatness. It simply makes fidelity possible when generating a hundred thousand words in months—a scale that used to destroy most projects before the Writer (+) could discover whether the book was worth finishing.

Leave a comment